|
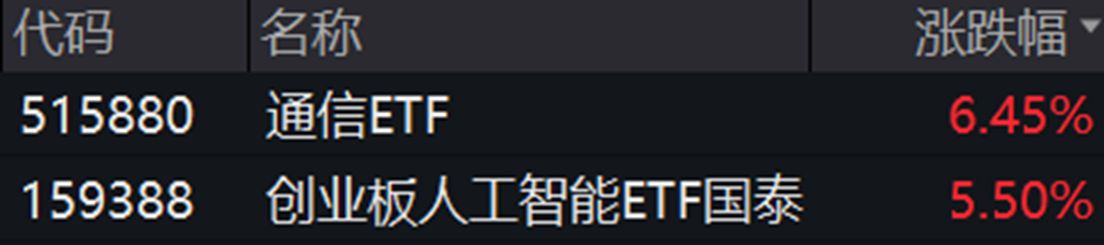
每经编辑|赵云 今日通信ETF(515880)开盘后持续上涨,全天维持强势,截至收盘上涨6.45%。创业板人工智能ETF国泰(159388)走势接近,收涨5.50%。
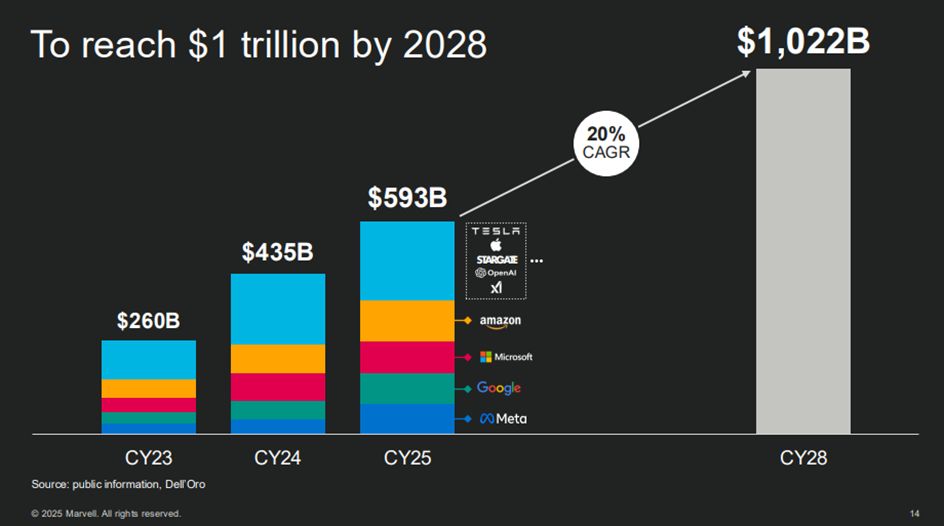
资料来源:wind 今日大盘表现强势。沪指突破去年10月8日高点,创近4年新高。沪深两市全天成交额2.15万亿,较上个交易日放量2694亿,时隔114个交易日重回2万亿上方。截至收盘,沪指涨0.48%,深成指涨1.76%,创业板指涨3.62%。AI今日获得市场认可,相关题材表现强势。 消息面上,Lumentum发布截至2025年6月28日的第四财季和整个财年业绩。Lumentum第四财季实现营收4.8亿美元,同环比+56%/+13%。云收入同环比+67%/+17%。作为上游核心供应商,其业绩超预期直接映射到光模块板块。 借着今日AI板块强势,想跟大家探讨一下:目前AI发展几何?后面还能持续么? 首先,回归本源,为什么token在快速增长? Scaling Law通常被译作缩放定律,这是OpenAI研究人员总结出来的一条规律,模型的性能与模型规模(参数量)、数据集规模、计算资源三者强相关。通俗的说,就是大力出奇迹,通过更大的模型、更多的语料、更深层的运算,模型性能可以平稳提升。 我们知道,大模型通常在预训练完成后会有一个后训练的过程,随后就会让用户使用。在早期,Scaling Law在预训练阶段大显身手,通过增加模型参数、增加训练语料等手段就实现了模型性能的本质飞跃。但是,随着优质语料的耗尽,Scaling Laws在预训练阶段的边际收益开始下滑。但随后,后训练、推理阶段的Scaling Laws开始发力。比如,当解决问题的时候,可以让基础模型分步骤去思考,一步一步得出答案。或者让模型多次推理,最后进行采样。实际上,OpenAI发布o1的时候,引起了巨大反响。o1并未以GPT冠名,主要原因便是技术路径发生了巨大的变化。从此,思维链开始成为了一种提升性能的重要途径。这就是Scaling Law在后训练和推理发力的重要表现。 Scaling Law直接让模型处理的token数量快速增长。Token,通俗的理解就是大模型的字符基本单位。比如我们在读书的时候要一个字一个字的读,大模型处理语言同样需要把字符分割成基本单位。 在大模型发展的过程中,token的增长并不是线性的。举个例子,在预训练过程中,模型需要多次迭代,通过梯度下降得到最优的参数集。所以,如果把模型参数增加,这时候整个训练过程所需要的计算量增加倍数会更大。而在推理阶段,这种增加甚至又被加速了,因为当模型性能开始提升时,不仅仅是单一用户使用模型的频率和单次使用的时间在增加,更重要的是,应用场景拓宽导致越来越多的用户参与了进来。以谷歌为例,在 5 月份的 IO大会,谷歌宣布每月处理 480 万亿个tokens,比起一年前增长了50多倍。而到了7月,这个数字再次翻倍,每月处理超过 980 万亿个token。 资料来源:华泰证券 遗憾的是,硬件的进化速度并没有算力需求那么快。摩尔定律表明“集成电路上可以容纳的晶体管数目在大约每经过18个月到24个月便会增加一倍”。且现在先进制程逐步接近物理极限,摩尔定律效能减弱。所以,为了赶上算力需求的增长,算力硬件开启了规模放量的进程。英伟达在GPU领域市占超过90%,也坐上了全球市值的龙头宝座。 第二,AI发展到顶了吗? 答案是没有。相反,现在仍处在早中期阶段。 从资本开支的角度来看,据华泰证券统计,北美四大云厂商(微软、亚马逊、Meta、谷歌)2025年第二季度合计资本开支同比增长69%至874亿美元,Factset一致预期25年资本开支将达到3338亿美元(同比+49%)。 可能有的投资者对3338亿美元这个数没有概念。以世界银行统计的2024年全球各国的GDP排名为例,3338亿美元的GDP大概能排到45名。更重要的是,即便是目前的资本开支,仍无法在短期内解决算力供应瓶颈的问题,所以,资本开支会进一步增长。Marvell预计,数据中心资本开支将在2028年达到一万亿美金,这个数字大概能在全球GDP排行榜上排在第20名。
资料来源:marvell 资本开支并没有打水漂。我们看到的是每个季度的电话会议上,北美四家云厂商都在表示,AI给他们的用户带来了新的体验,并且愿意为了他们的产品付费。这一点,从云厂商每个季度都有双位数幅度增加的业绩就可以看出来。 从软件端看,2025年以来,伴随英伟达GB200机架量产出货,算力资源的紧缺有所缓解。软件端,在今年也迎来了明显加速。谷歌今年发布的Gemini2.5系列、Genie3等模型,再次让业界看到了长远的可能性。Genie3在世界模型的大道上前进了一大步,它不仅仅是一个视频生成器,而是试图让生成的场景连贯,试着去理解物理学的基本定律。可以想象,Genie3可以将2D的图片拓展到三维空间,若其运算速度和性能进一步提升,可能对于智能驾驶、人形机器人这些领域的发展产生难以忽视的影响。谷歌一直是AI领域的领导者,其DeepMind团队此前凭借AlphaGO击败世界围棋冠军,名冠当世。去年又因为在蛋白质结构预测领域的贡献斩获诺贝尔化学奖,没想到一年之后,又再次让世界惊艳。而其他厂商,如xAI、微软、阿里等也在积极推进软件研发。 大模型的爆火。从2023年到现在已经两年多了。以英伟达的产品划分,在2023年-2024年,AI下游使用的GPU主要是Hopper(H100、H200),而到现在,新一代的Blackwell架构产品开始主导。在Hopper时代,云厂商巨额的资本开始不禁让人质疑它的持续性,因为那时AI的闭环还很朦胧,人们没有看到这些云厂商要通过什么方式来回收他们的成本。但到了Blackwell时代,AI进入到了新的阶段,云厂商的业绩高速增长,AI对他们的赋能已经显而易见,换言之,AI的模式已经跑通,接下来是更高更快更远。软件和硬件共振,训练和推理共振,AI或许会进一步拓宽应用场景和增加用户数量,相关的需求或进一步推动AI基建。站在当下,我们看到AI仍然处在上升通道。 第三,怎么选择投资品?为什么要关注光模块? 目前大模型参数量已经达到了万亿参数规模,每次完成训练和推理都需要面临庞大的运算量,所以,厂商无法依靠单一的GPU或者AI服务器完成这么庞大的运算。解决方法是组网。 以英伟达的架构为例,网络的目标是将大的计算任务分割,然后分发到每一片GPU上运算,最后再交互结果。所以,组网的第一步,是将GPU组成一个AI服务器。这个过程是使用NVLink技术来完成的,在Blackwell架构中,介质就是铜缆。 铜缆传输高速,功耗小,优点显著。但没有什么东西是完美的,铜缆也有其固有的缺点。比如,在面对数据中心的高频高速信号时,铜缆无法完成长距离传输的任务。由于“趋肤效应”,信号会集中在导体的表面,传输的有效横截面变小,发热等问题被放大,数据丢包等问题开始变得不可忍受。 工程师说,要有光,于是就有了光模块。光模块的任务是将电信号转变为光信号,使得其能长距离传输。这样,AI服务器便可以进一步组装成为大规模集群,完成复杂的运算。换言之,光模块是数据中心组网过程中不可或缺的。由于全球产业链分工的关系,光模块的核心份额聚焦在中国大陆,北美相关厂商的需求,也主要是由中国大陆的企业来完成。所以,光模块无疑是A股的AI行情中的核心环节之一。这一点,我们也从龙头公司高速增长的业绩中看到了,并且,我们认为业绩仍有较大的增长空间。 产品层面,通信ETF(515880)标的指数的光模块占比超过40%,加上服务器、铜连接等占比超过60%,光模块占比应该是目前主流人工智能指数和通信指数中最高的。而创业板人工智能ETF国泰中也含有较多的光模块成分,而且有20cm的弹性。 目前全球的科技巨头都在AI战场上角逐,且北美目前已经跑通了这条道路,AI或许真的能改变我们的生活。同时,A股的光模块又是在全球产业链分工中占据了核心地位的环节,在A股慢牛的过程中,其表现代表了市场对AI这一产业趋势的认可程度。建议投资需围绕关键环节展开,继续关注通信ETF(515880)、创业板人工智能ETF国泰(159388)。 风险提示 本速评已力求报告内容的客观、公正,但对这些信息的准确性和完整性不作任何保证,文中的观点、结论和建议仅供参考,相关观点不代表任何投资建议或承诺。行业或板块短期涨跌幅列示仅作为市场行情分析的辅助材料,仅供参考,不构成投资建议或承诺。文中涉及个股仅用于行业表现说明,非个股推荐。 我国基金运作时间较短,不能反映股市发展的所有阶段。基金管理人承诺以诚实信用、勤勉尽责的原则管理和运用基金资产,但不保证本基金一定盈利,也不保证最低收益。基金的过往业绩及其净值高低并不预示其未来业绩表现。基金管理人提醒投资人基金投资的“买者自负”原则,在做出投资决策后,基金运营状况与基金净值变化引致的投资风险,由投资人自行负担。基金有风险,购买过程中应选择与自己风险识别能力和承受能力相匹配的基金,投资需谨慎。 投资人应当充分了解基金定期定额投资和零存整取等储蓄方式的区别。定期定额投资是引导投资人进行长期投资、平均投资成本的一种简单易行的投资方式。但是定期定额投资并不能规避基金投资所固有的风险,不能保证投资人获得收益,也不是替代储蓄的等效理财方式。 |