|
OpenAI发布ChatGPT Agent:部分能力超越人类 但做电子表格仍不如人类 全新妙想投研助理,立即体验 7月,OpenAI尚未按照此前计划发布GPT-5,智能体方面的更新先行面世了。 北京时间7月18日凌晨,OpenAI直播发布了ChatGPT Agent,这一智能体融合了Operator智能体网页交互能力以及Deep Research功能,使ChatGPT内置计算机能帮助用户完成复杂的多步骤任务。 “现在ChatGPT可以思考和行动,能主动从技能工具箱中选择工具,完成一些任务。”OpenAI介绍,这些任务包括“查看我的日历并根据近期新闻介绍即将举行的会议”“分析三个竞争对手并创建幻灯片”等。此外,用户还可以执行一些重复任务,例如将屏幕截图转换为可编辑PPT、用新的财务数据更新电子表格、重新安排会议。 据介绍,ChatGPT的工作过程包括浏览网站、过滤结果、提醒用户登录相关账号、运行账号、分析、创建电子表格和幻灯片。 此前OpenAI曾单独发布Operator和Deep Research功能,其中Operator也是一个智能体,可以滚动、点击网页,帮用户完成餐厅预订等任务,Deep Research则主要面向信息深度分析和整合任务。OpenAI称,此次ChatGPT的核心更新是创建了一个统一的智能体系统,使Operator调动网站的能力、Deep Research整合信息的能力、ChatGPT对话能力融为一体。此次发布的智能体系统可以调用可视化浏览器、文本浏览器、终端工具、API接口,分别可用于与网页交互、处理大量文本、运行代码或下载文件、访问GitHub等应用数据。 从基准测试表现看,在跨学科专家级测试Humanitys Last Exam中,ChatGPT Agent回答准确率为41.6%,超过Deep Research的26.6%、o3模型的24.9%;在数学基准测试FrontierMath中,ChatGPT Agent准确率为27.4%,高于o4 mini的19.3%和o3的10.3%;在针对真实知识工作任务的内部评测中,ChatGPT Agent在约半数案例中的表现与人类持平或超过人类;在现实数据科学任务DSBench测试中,ChatGPT的分析与建模准确率分别为89.9%和85.5%,超过人类水平;在衡量模型承担一到三年投资银行分析师建模任务能力的内部基准上,准确率高于o3和Deep Research。 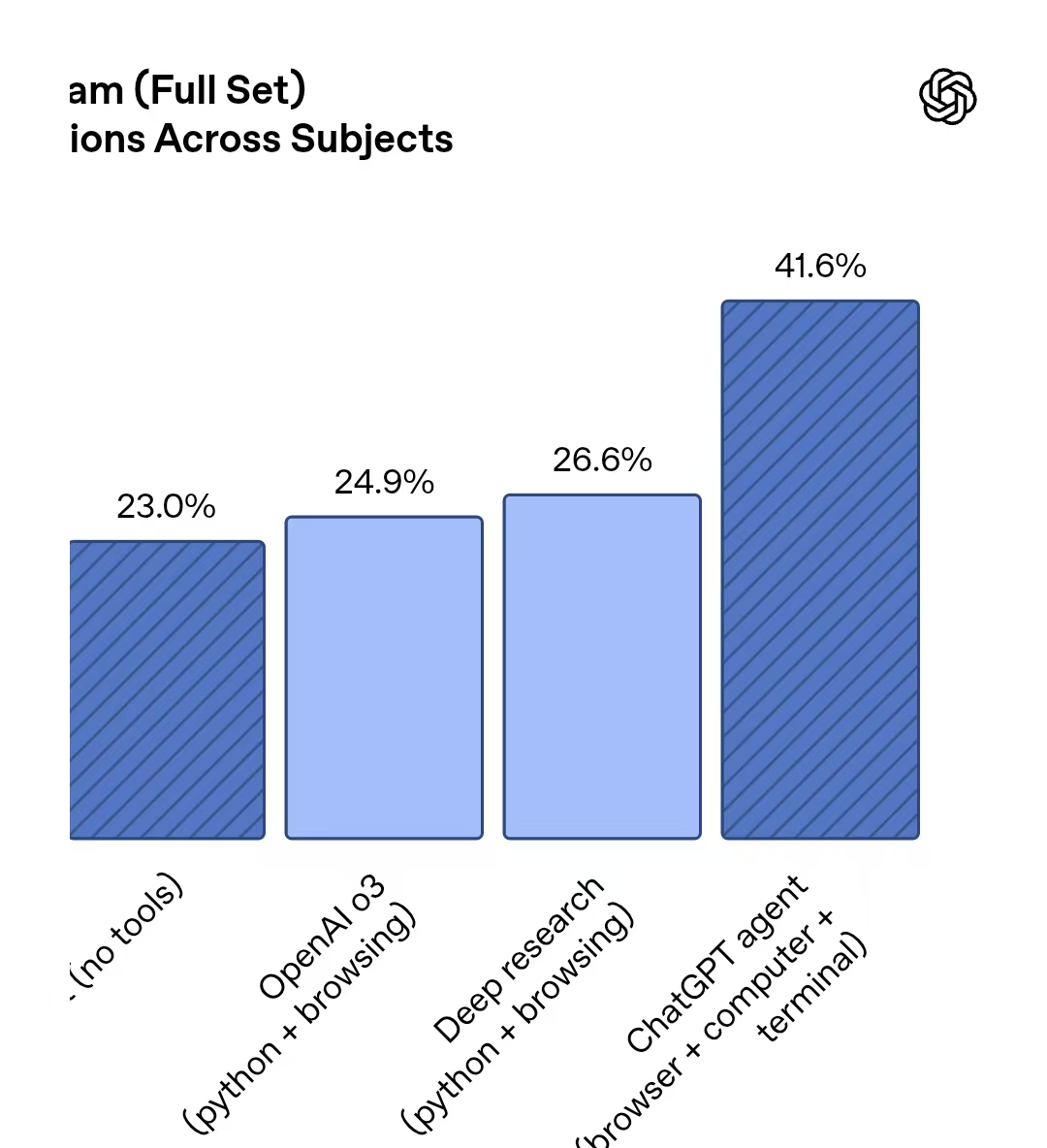 不过,虽然ChatGPT Agent在SpreadsheetBench测试(评估模型编辑真实场景电子表格的能力)中,表现超过OpenAI的其他模型,但其最高得分45.5%还是远低于人类得分71.3%。 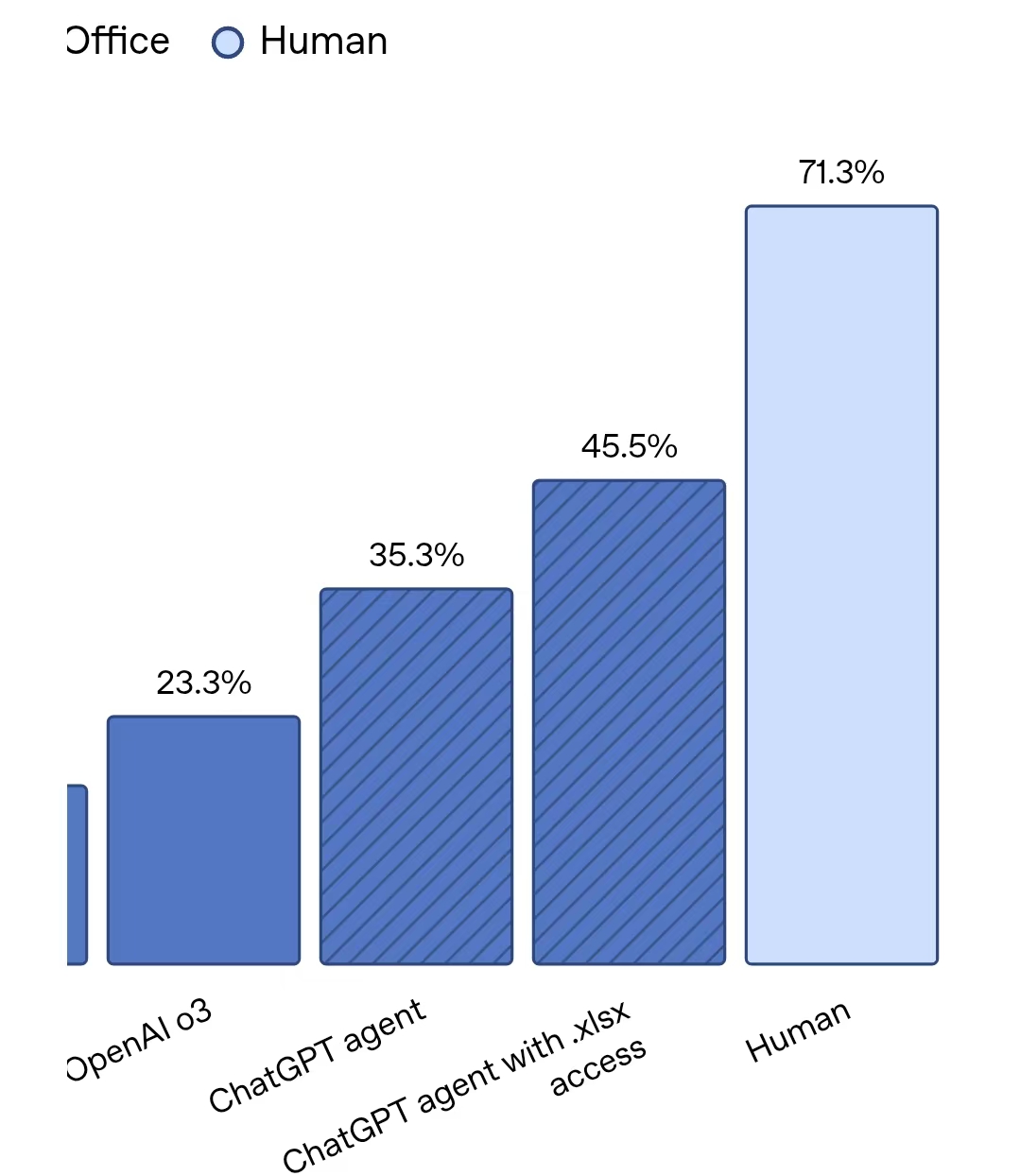 OpenAI称,此次更新是一个开始,公司将继续定期迭代改进。 Agent的能力很大程度上取决于基础模型的能力。发布ChatGPT Agent后,OpenAI最受关注的更新还是推出GPT-5。此前OpenAI CEO奥尔特曼表示,GPT-5可能于今年夏天推出,OpenAI代表此前也曾透露,初步预计的发布时间是在今年7月。当前,面对来自DeepSeek等厂商的竞争,OpenAI还是需要通过推出新的基础模型来证明自身的领先地位。 从Agent演进上看,有Agent开发者告诉记者,今年Agent预计可以在数十步较复杂的工具调用中,做到90%的准确率,基本达到可商用状态。但基础模型的能力还是还有所欠缺,基础模型还难以做到自主调用上万个工具并自主执行。 想炒股,先开户!选丁冬财经证券,行情交易一个APP搞定>> (文章来源:第一财经) |



半小时前

1 小时前

1 小时前

1 小时前


7月29日,苹果中国官网显示,位于大连百年城的Apple Store 店将于今年8月9日20:00

中国外交部发言人郭嘉昆29日主持例行记者会。 有记者提问:据俄罗斯消息人士称

今年暑期档第一部大热影片来了。 灯塔平台数据显示,截至7月29日15时,电影《

7月29日,三大指数早盘表现分化,午后均震荡上行,截至收盘,沪指涨0.33%,深证成

7月29日,雷军发微博祝贺中国长安汽车(000625)集团正式挂牌!雷军称:“长安汽车的历

周二,黄金价格连跌四天后勉强起稳,目前交投于3313美元/盎司,从技术层面来看,黄金

近期全国多地降雨频繁,外出时应注意避让路面积水,谨慎出行,安全第一!

每经记者|熊嘉楠每经编辑|彭水萍 7月29日8时许,仁怀市酒业协会(以下简称“仁怀

每经记者|李星每经实习编辑|余婷婷 近日,华东、华北、东北等地持续遭遇强降雨,

煤炭传来大消息! 7月29日午后,煤炭板块异动明显。煤炭ETF由跌转涨,一度涨近













