|
凤凰网科技讯 6月28日,阿里云通义千问刚刚发文,宣布推出最新的多模态统一理解与生成模型Qwen VLo。这一全新升级的模型可以进行高质量的再创造,实现从感知到生成的跨越。
官方表示,Qwen VLo采用动态分辨率训练,支持动态分辨率生成。无论是输入端还是输出端,模型都支持任意分辨率和长宽比的图像生成。这意味着用户不再受限于固定的格式,可以根据实际需求生成适配不同场景的图像内容。 此外,Qwen VLo还创新性地引入了一种全新的生成机制:从上到下、从左到右逐步清晰的生成过程。这一机制不仅提升了生成效率,还特别适用于需要精细控制的长段落文字生成任务。 阿里云官方提醒,Qwen VLo属于预览阶段,还有很多不足的地方,在生成的过程可能存在不符合事实、不完全和原图一致的问题,开发团队还在持续迭代。 (责任编辑:郭健东 )
【免责声明】本文仅代表作者本人观点,与和讯网无关。和讯网站对文中陈述、观点判断保持中立,不对所包含内容的准确性、可靠性或完整性提供任何明示或暗示的保证。请读者仅作参考,并请自行承担全部责任。邮箱:news_center@staff.hexun.com |

1 小时前
1 小时前

1 小时前

1 小时前

1 小时前

每经编辑|程鹏 向江林 手机芯片,进入2nm时代! 据财联社12月21日报道,三星在全

每经编辑|黄胜 央视新闻消息,针对俄罗斯总统普京有关“乌克兰政府须通过选举获得

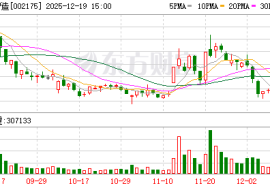
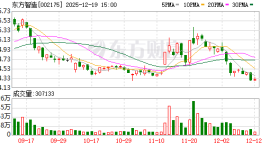
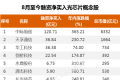
两只A股公司迎来国资入局。 12月19日晚间,东方智造(002175)、中国高科(600

12月18日,海南自由贸易港全岛封关正式启动,封关首日下午,苹果、华为门店排起长

沪深两市多家上市公司12月21日晚间发布公司公告,以下为重要公告汇总。 【品大

沪深两市多家上市公司12月21日晚间发布重要公告,以下为利好的消息汇总: 观想

每经编辑|黄胜 央视新闻消息,泰国总理阿努廷21日说,在军事层面,泰国三军武装部

手机芯片,进入2nm时代! 芯片领域,传来一则重磅消息:日前,三星电子正式推
中国光计算芯片领域又取得重大突破! 据新华社消息,上海交通大学科研人员近日

A股市场本周(12月15日至19日)整体呈现V型走势,沪指凭借三连阳,堪堪收复周初失